Gordon Qian is a research scientist at Snap Research Creative Vision team, working on Generative Models. He earned his Ph.D. in Computer Science from KAUST, where he was fortunate to be advised by Prof. Bernard Ghanem.
He has authored 19 top-tier conference and journal papers, including one first-authored work with over 1,100 citations and three first-authored works with over 300 citations each.
In total, his publications have received over 3200 citations, and his current h-index is 19.
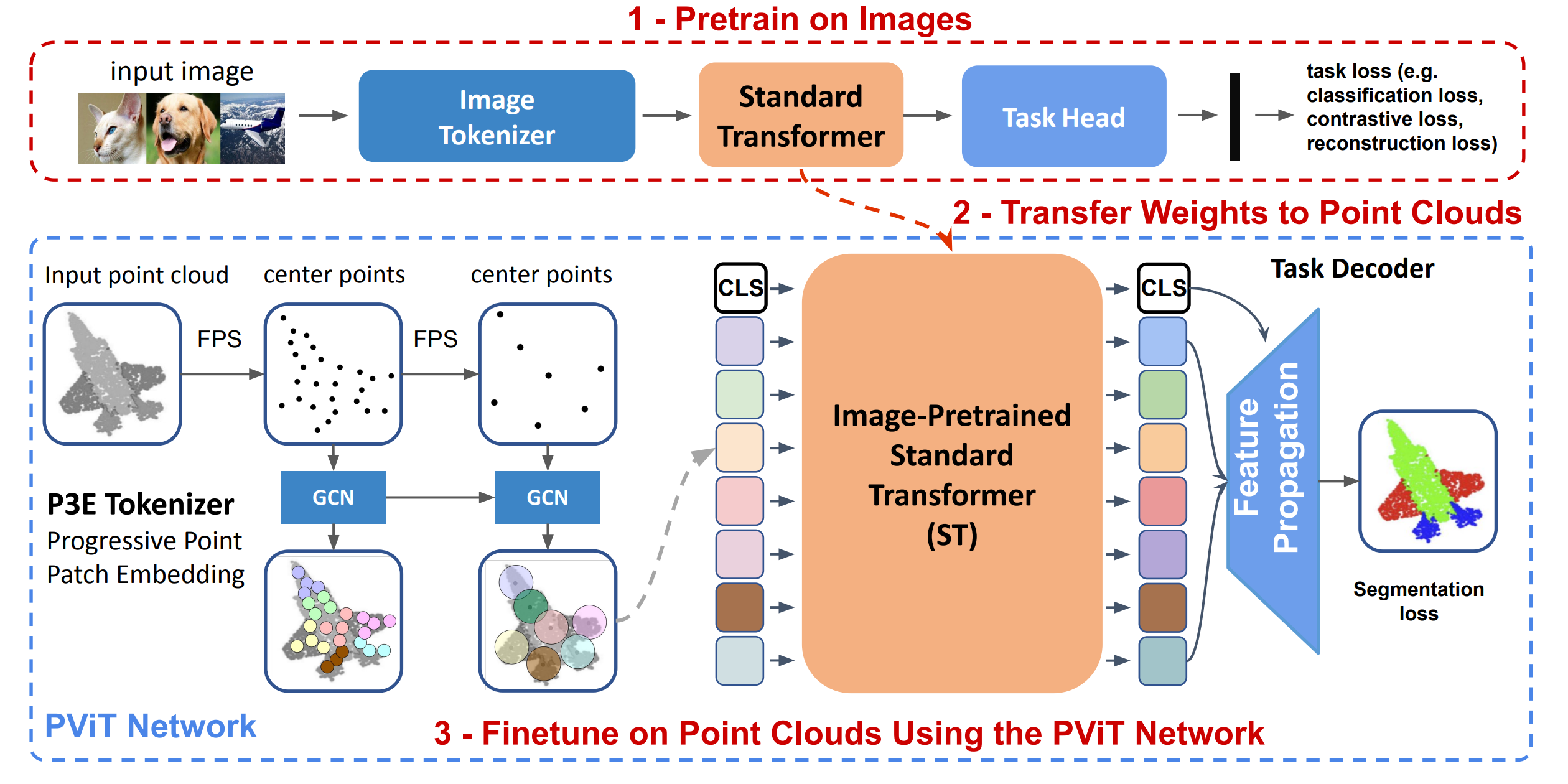
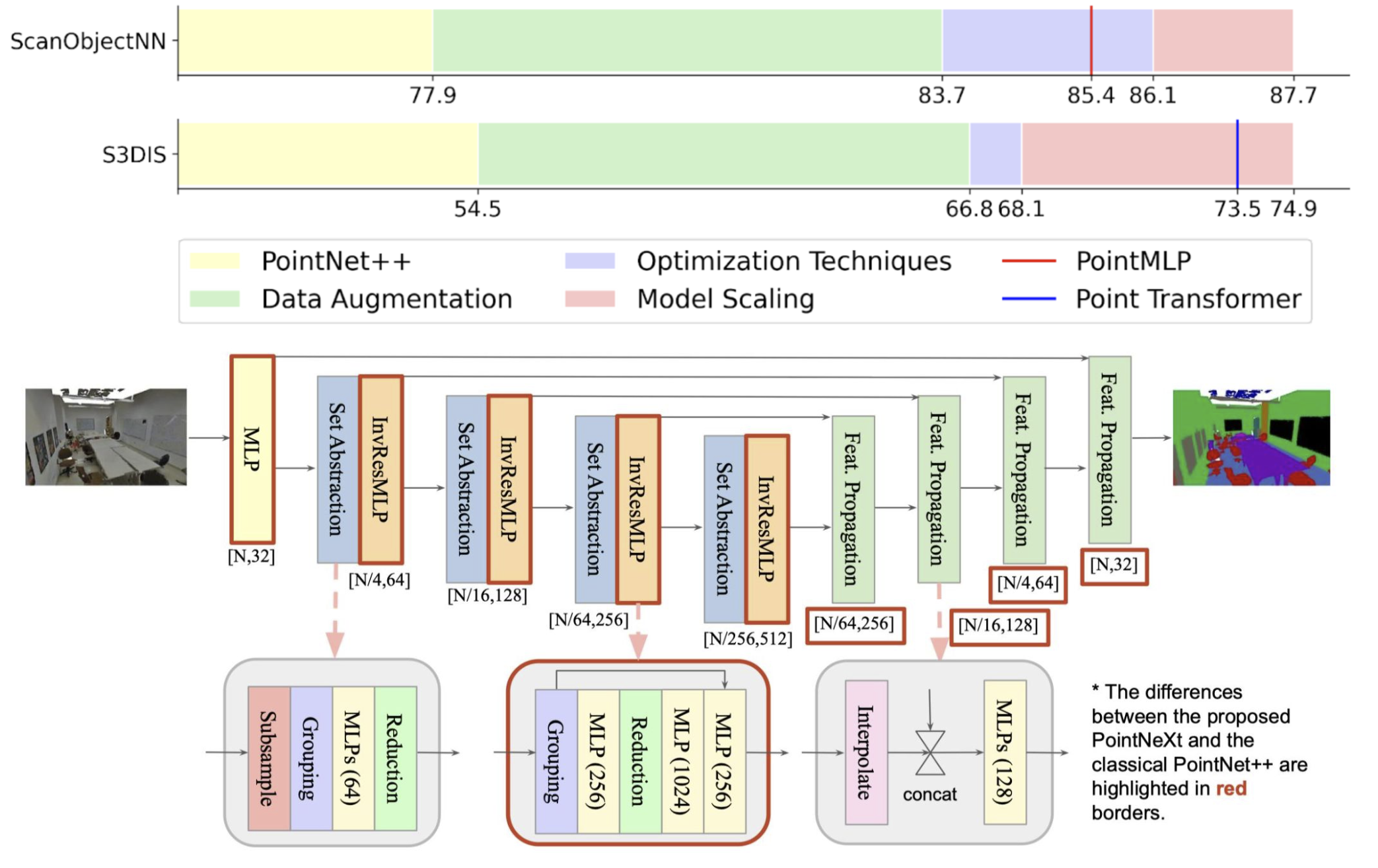
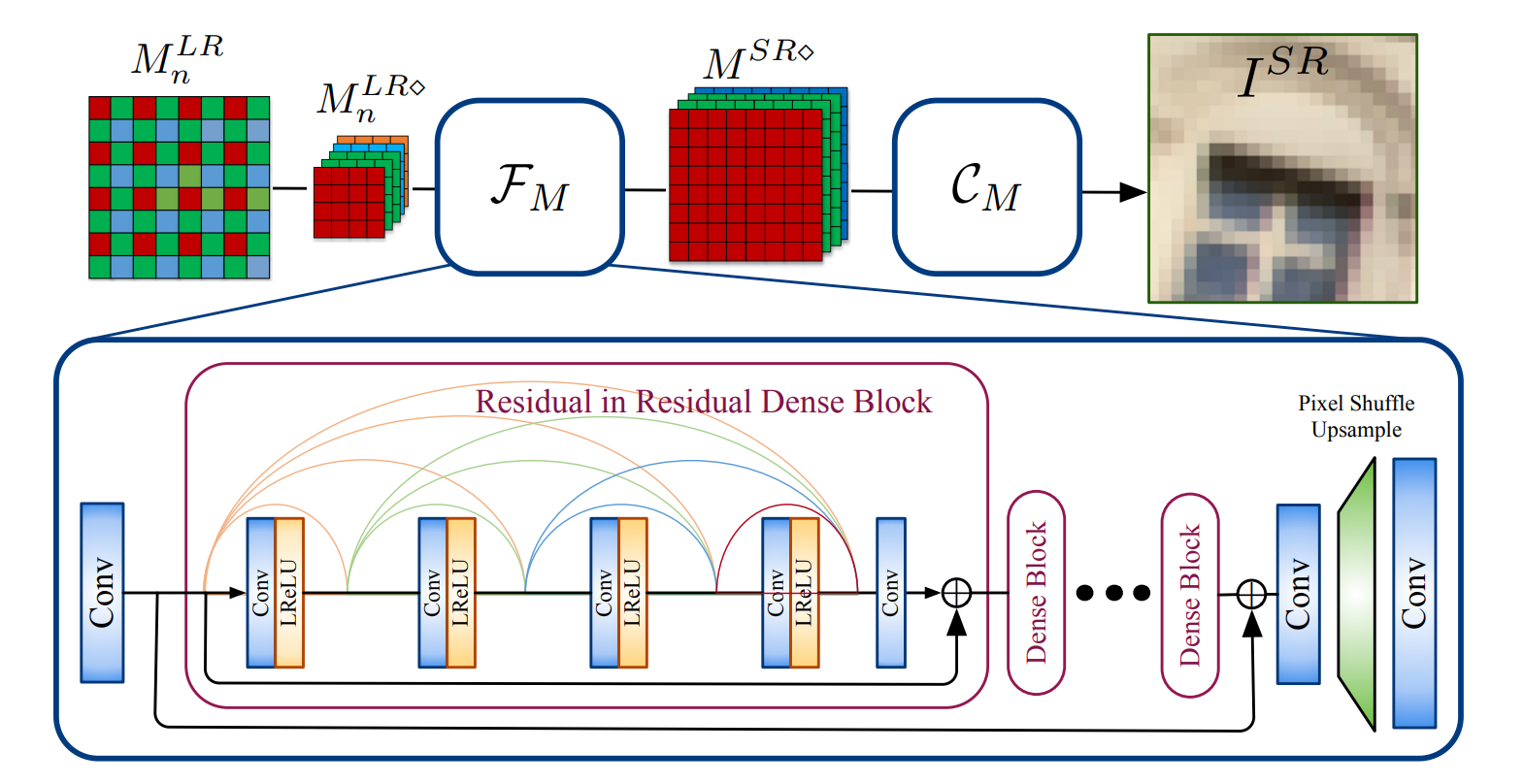
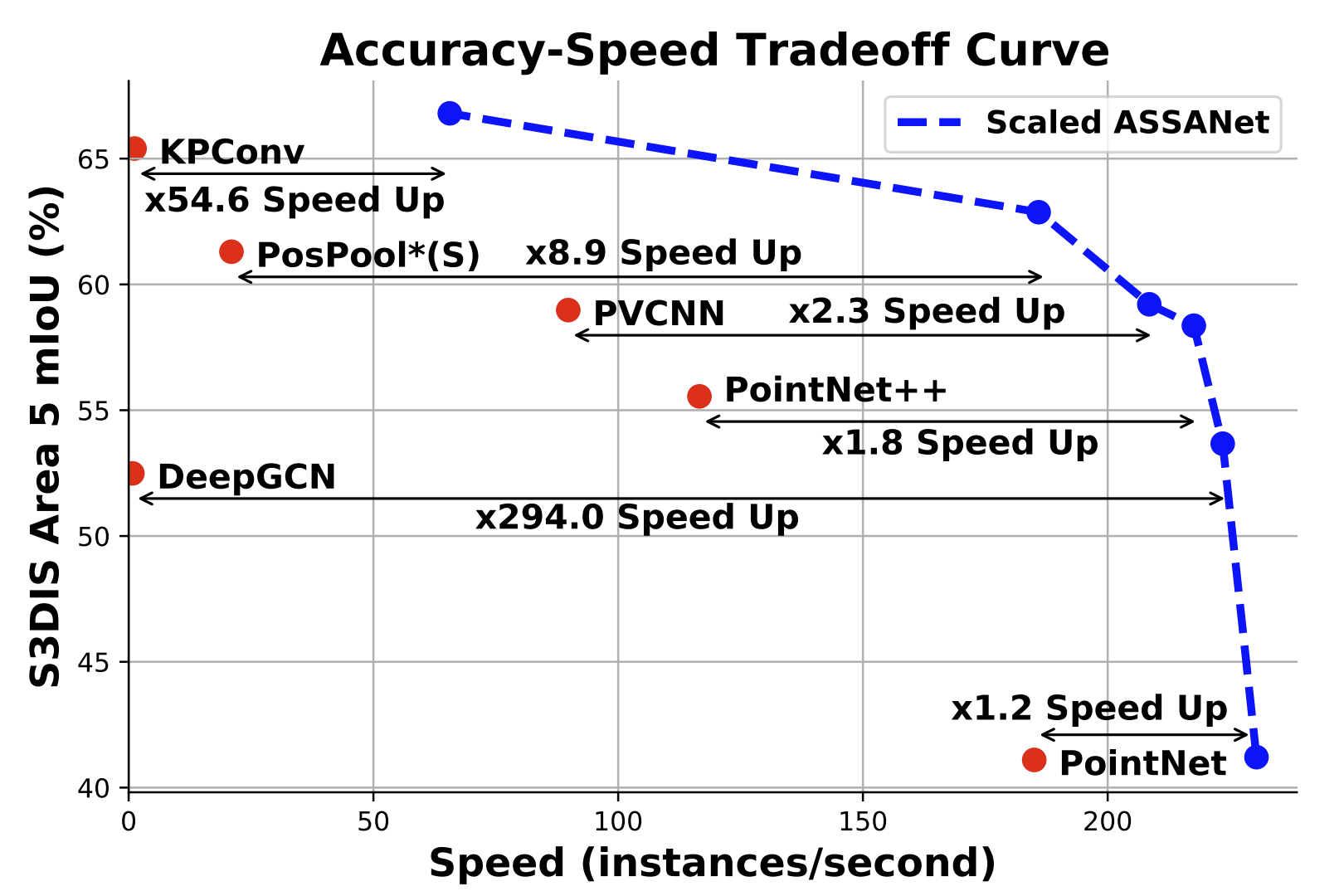
His representative work includes PointNeXt (NeurIPS, >1100 cites, >900 GitHub stars), Magic123 (ICLR, >450 cites, >1.6K GitHub stars) and Omni-ID (CVPR'25, products integrated into Snapchat).
He also serves as area chair for ICLR starting from 2025.
If you are interested in working in image/video generative models with me, please reach out at guocheng.qian [at] outlook.com
Education

Ph.D. in CS
KAUST , 2019 - 2023

B.Eng in ME
XJTU , 2014 - 2018