01
Video Generation
Now post-training Seedance at ByteDance. Previously worked on video pretraining, post-training (camera control, editing), and alignment tuning.
Gordon Guocheng Qian is a Staff Researcher at ByteDance, where he works on post-training of Seedance video generation models. Previously, he was a Senior Research Scientist at Snap Inc., where he worked on video generation pretraining and post-training and served as tech lead for personalized generation, filing six patents and shipping three research innovations to Snapchat products (Dreams, EasyLens, and AI Lens), impacting 900M+ monthly active users. He earned his Ph.D. in Computer Science from KAUST, advised by Prof. Bernard Ghanem.
He has authored 20+ top-tier publications with 4,000+ citations.
His representative works include PointNeXt (NeurIPS, 1.2K+ citations, 1K+ GitHub stars), Magic123 (ICLR, 450+ citations, 1.6K+ GitHub stars), and Omni-ID (CVPR, product integrated, patent filed). His research interests include streamable and unified multimodal understanding and generation. He serves as an Area Chair for ICLR and NeurIPS.
If you are interested in working on image and video generative models with me, please reach out at gordonqian2017 [at] gmail.com
Ph.D. in CS
KAUST, 2019 - 2023
B.Eng in ME
XJTU, 2014 - 2018
Now post-training Seedance at ByteDance. Previously worked on video pretraining, post-training (camera control, editing), and alignment tuning.
Tech lead of full-stack R&D. Shipped three products and filed three patents.
Worked on VLM post-training, VLM diffusion, and VLM-based reward tuning.
Worked across image-to-3D and text-to-3D generation, including high-impact systems for geometry, mesh generation, and controllable 3D content.
First-authored multiple projects on scalable spatial understanding and efficient 3D representation learning.
Selected projects below; * / † denote equal contribution / corresponding author. See Full publication list .
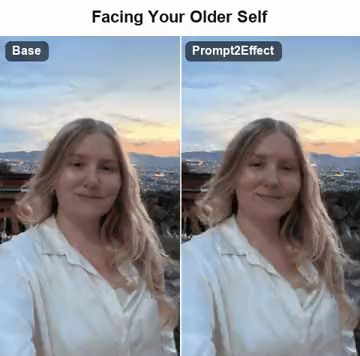
Prompt2Effect synthesizes effect-specific LoRA weights for image-to-video diffusion models in a single forward pass, reducing per-effect specialization from 56 GPU hours to 3.3 seconds.

Canvas-to-Image introduces a unified framework that consolidates heterogeneous controls (subject references, bounding boxes, pose skeletons) into a single canvas interface for high-fidelity compositional image generation.

Diffusion-DRF uses a frozen VLM critic to provide free, rich, and differentiable feedback for stable video diffusion fine-tuning.

EasyV2V: A high-quality instruction-based video editing framework that enables intuitive video manipulation through natural language instructions.

Omni-Attribute can isolate a specific attribute, whether it is an abstract concept or not, from any image and merge those selected attributes from multiple images into a coherent generation.

We prevent shortcuts in adapter training by explicitly providing the shortcuts during training, forcing the model to learn more robust representations.
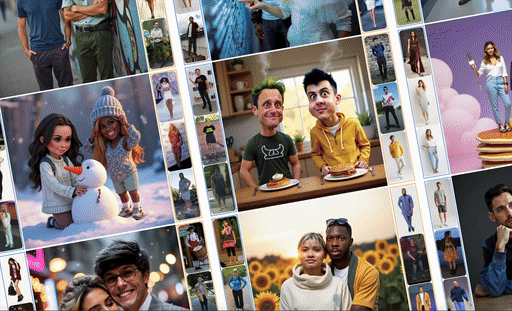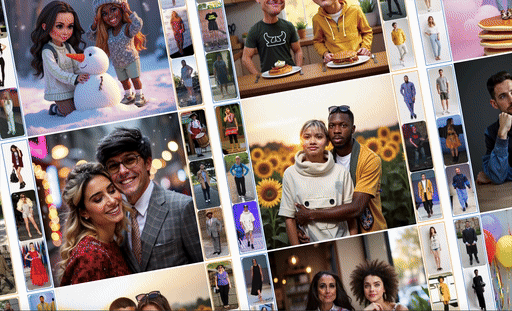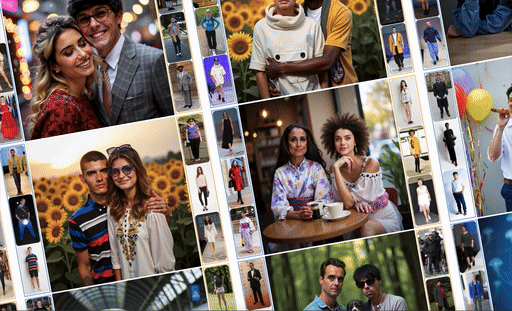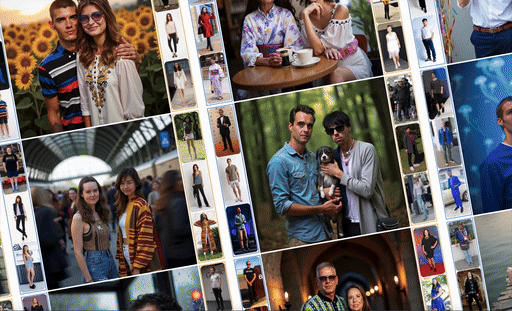
ComposeMe is a human-centric generative model that enables disentangled control over multiple visual attributes — such as identity, hair, and garment — across multiple subjects, while also supporting text-based control.

ThinkDiff enables multimodal in-context reasoning in diffusion models by aligning vision-language models to LLM decoders, transferring reasoning capabilities without requiring complex reasoning-based datasets.

Omni-ID is a novel facial representation tailored for generative tasks, encoding identity features from unstructured images into a fixed-size representation that captures diverse expressions and poses.

WonderLand is a video-latent based approach for single-image 3D reconstruction in large-scale scenes.

AC3D studies when and how you should condition camera signals into a video diffusion model for a better camera control and a higher video quality.



Magic123 proposes a hybrid score distillation algorithm and a coarse-to-fine image-to-3D pipeline that produces high-quality high-resolution 3D content from a single unposed image.
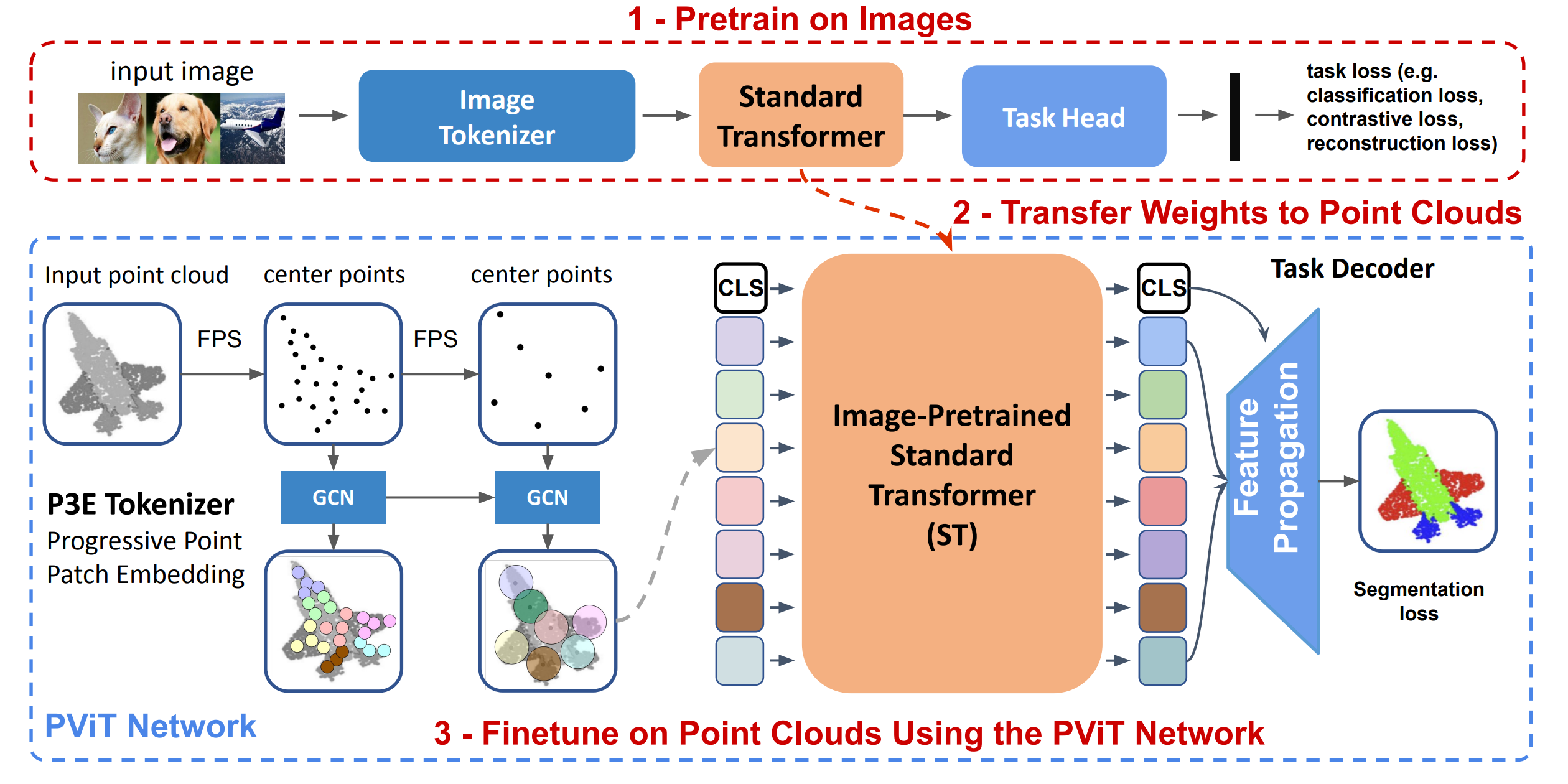
Pix4Point shows that image pretraining significantly improves point cloud understanding.
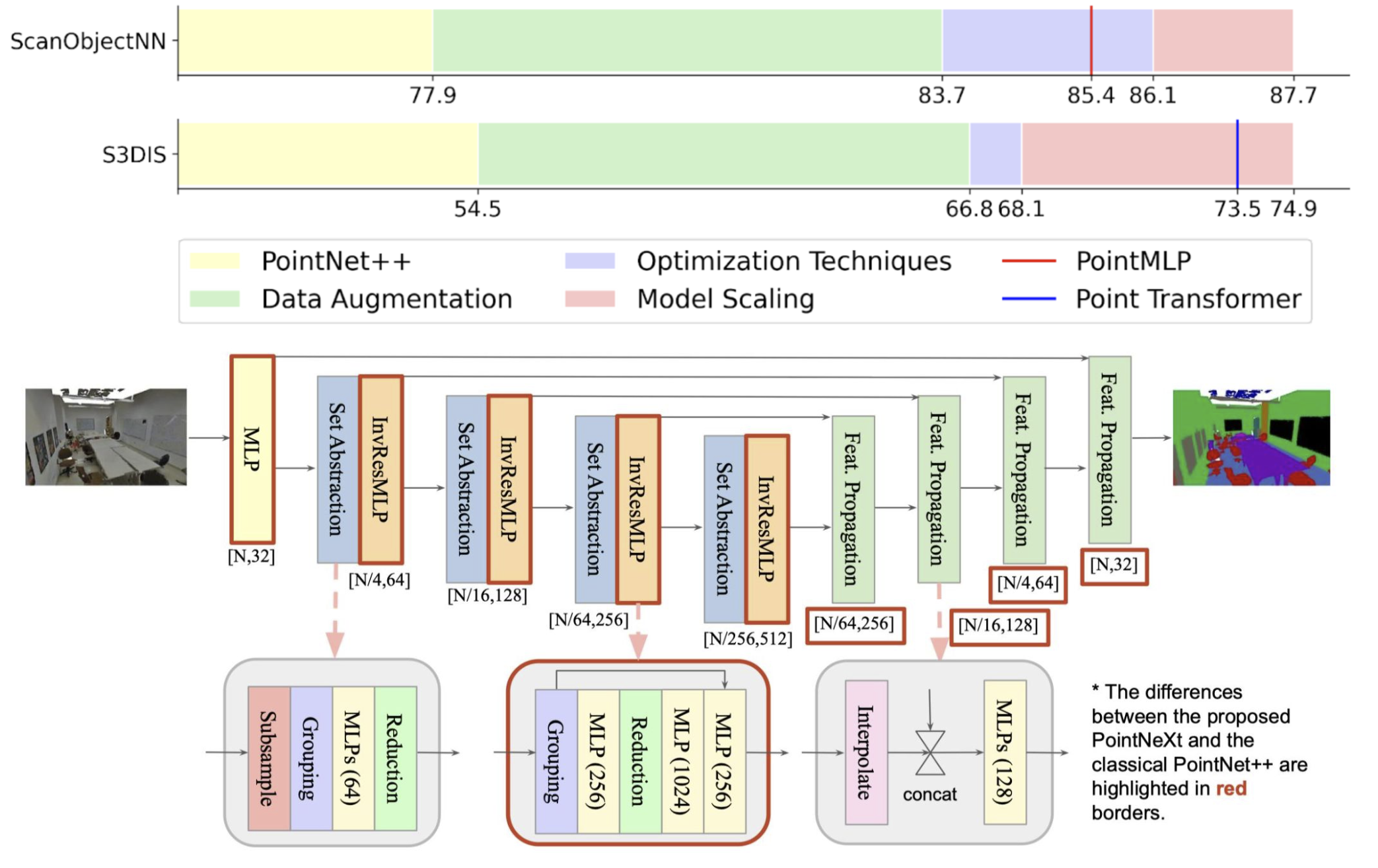


PointNeXt boosts the performance of PointNet++ to the state-of-the-art level with improved training and scaling strategies.
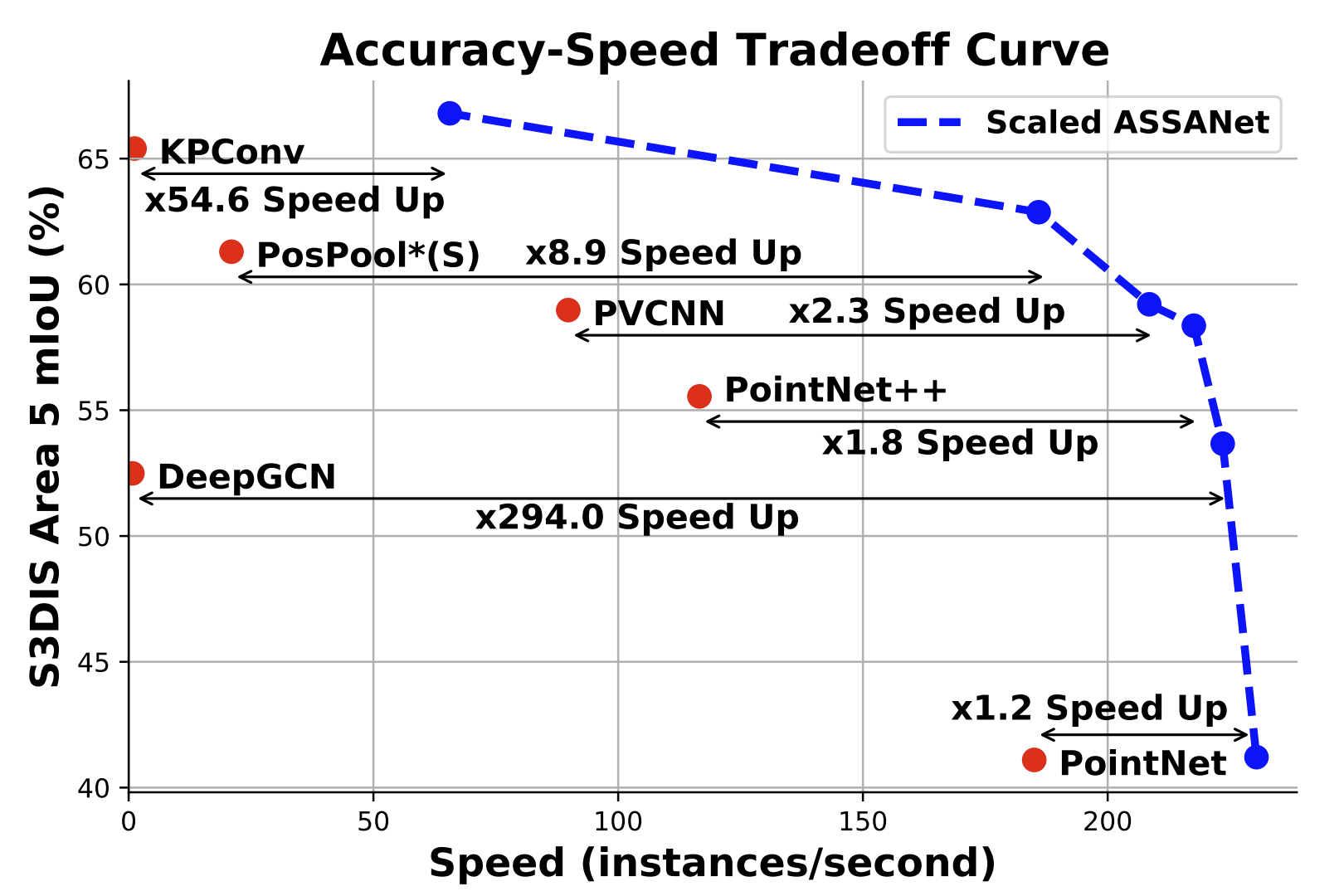

ASSANet makes PointNet++ faster and more accurate.