Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
ICLR 2024


Abstract
We present "Magic123", a two-stage coarse-to-fine solution for high-quality, textured 3D meshes generation from a single unposed image in the wild using both 2D and 3D priors. In the first stage, we optimize a neural radiance field to produce a coarse geometry. In the second stage, we adopt a memory-efficient differentiable mesh representation to yield a high-resolution mesh with a visually appealing texture. In both stages, the 3D content is learned through reference view supervision and novel views guided by both 2D and 3D diffusion priors. We introduce a single tradeoff parameter between the 2D and 3D priors to control exploration (more imaginative) and exploitation (more precise) of the generated geometry. Additionally, We employ textual inversion and monocular depth regularization to encourage consistent appearances across views and to prevent degenerate solutions, respectively. Magic123 demonstrates a significant improvement over previous image-to-3D techniques, as validated through extensive experiments on synthetic benchmarks and diverse real-world images.
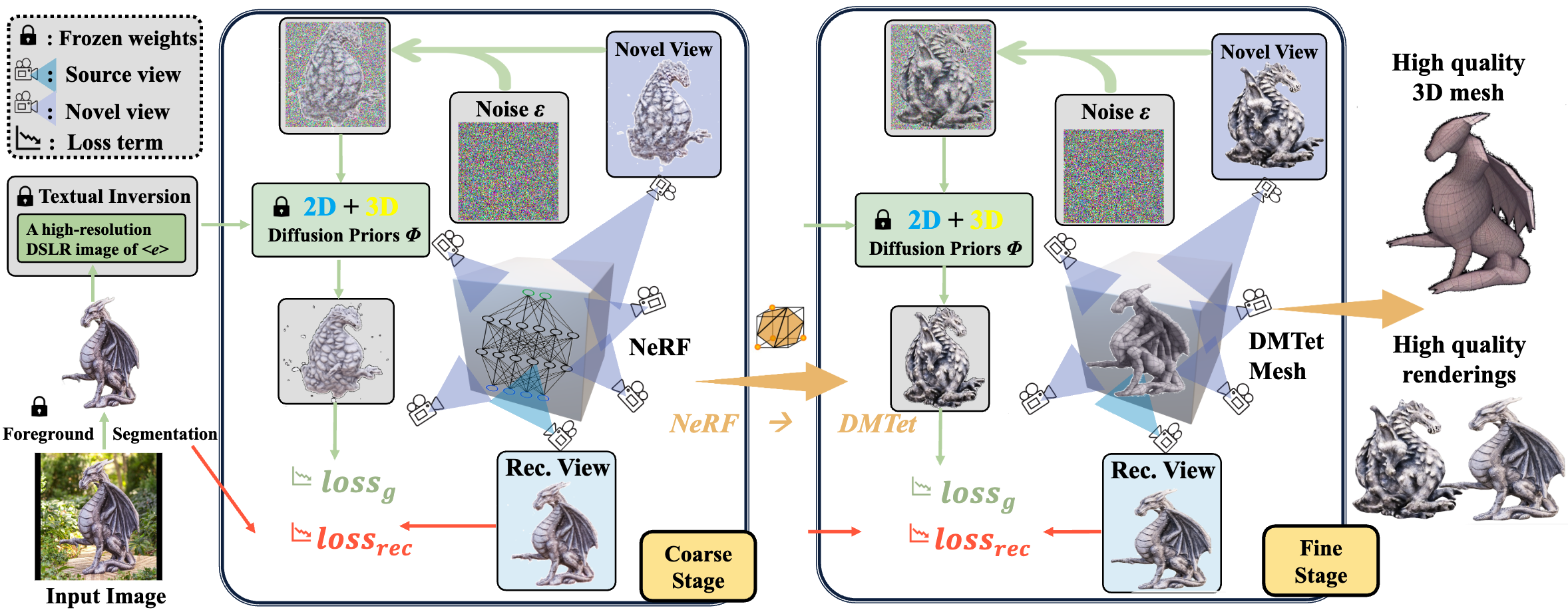
Magic123 pipeline. Magic123 is a two-stage coarse-to-fine framework for high-quality 3D generation from a reference image. Magic123 is guided by the reference image, constrained by the monocular depth estimation from the image, and driven by a joint 2D and 3D diffusion prior to dream up novel views. At the coarse stage, we optimize an Instant-NGP neural radiance field (NeRF) to reconstruct a coarse geometry. At the fine stage, we initialize a DMTet mesh from the NeRF output and optimize a high-resolution mesh and texture directly. Textural inversion is used in both stages to generate object-preserving geometry and view-consistent textures.
Example generated objects
Magic123 generates photo-realistic 3D objects from a single unposed image.




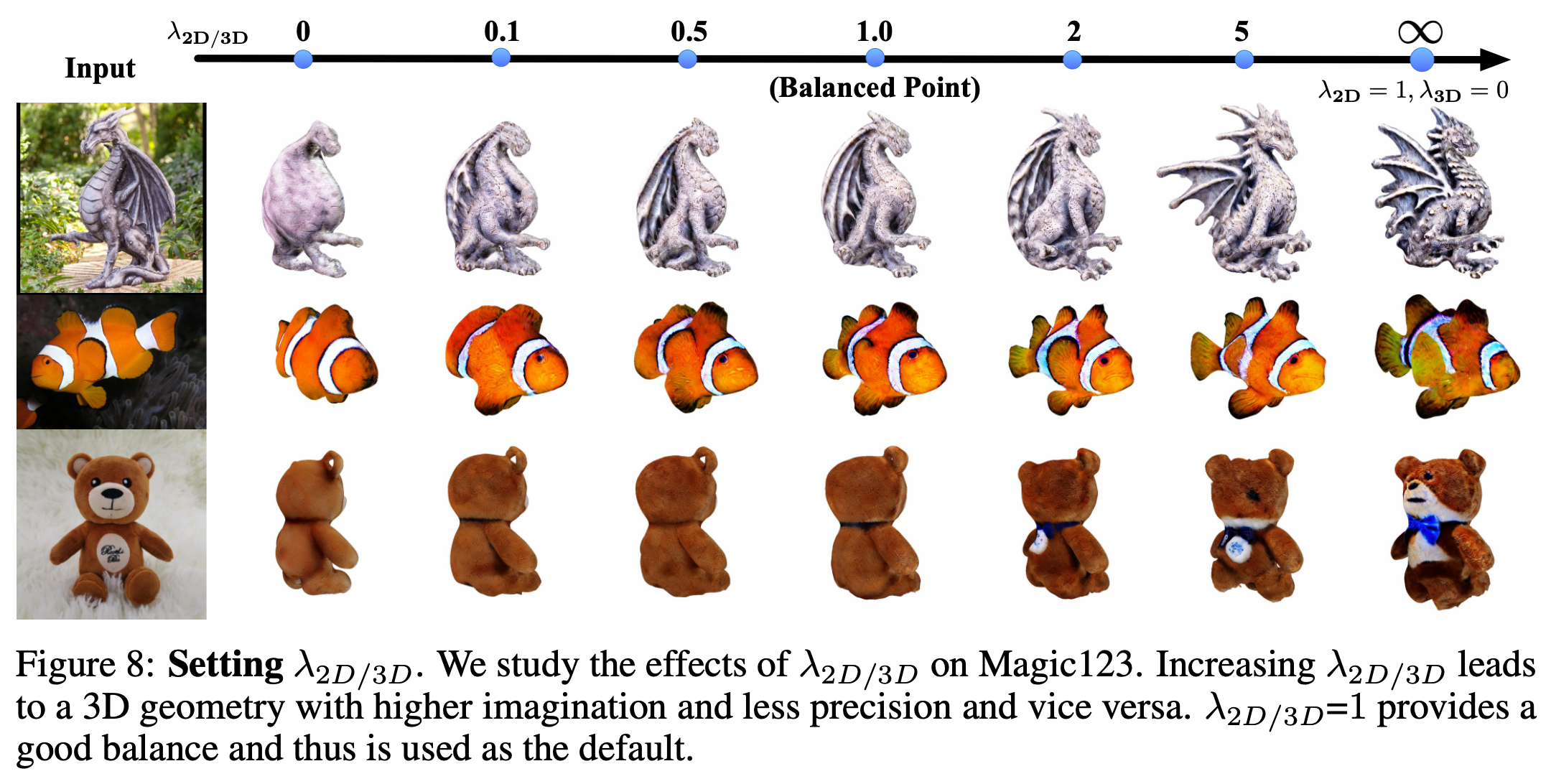
Tradeoff between 2D and 3D priors in Magic123
We compare single image reconstructions for three cases: a cactus (common object), two stacked donuts (less common object), and a dragon statue (uncommon object). Magic123 with only 2D prior (on the right) favors geometry exploration, generating 3D content with more imagination but potentially lacking 3D consistency. Magic123 with only 3D prior prioritizes geometry exploitation, resulting in precise yet potentially simplified geometry with reduced details. Magic123 thus proposes to use both 2D and 3D prior and introduces a tradeoff parameter \( \lambda_{2D/3D} \) to control the geometry exploration and exploitation. We provide a balanced point \( \lambda_{2D/3D}=1 \) , with which Magic123 consistently offers identity-preserving 3D content with fine-grained geometry and visually appealing texture.

Effects of the coarse-to-fine pipeline
Qualitative comparisons of the coarse and fine stages between Magic123 with only 2D prior \( \lambda_{2D}=1,\lambda_{3D}=0 \), Magic123 with only 3D prior \( \lambda_{2D}=0,\lambda_{3D}=40 \), and Magic123 \( \lambda_{2D}=1,\lambda_{3D}=40 \).

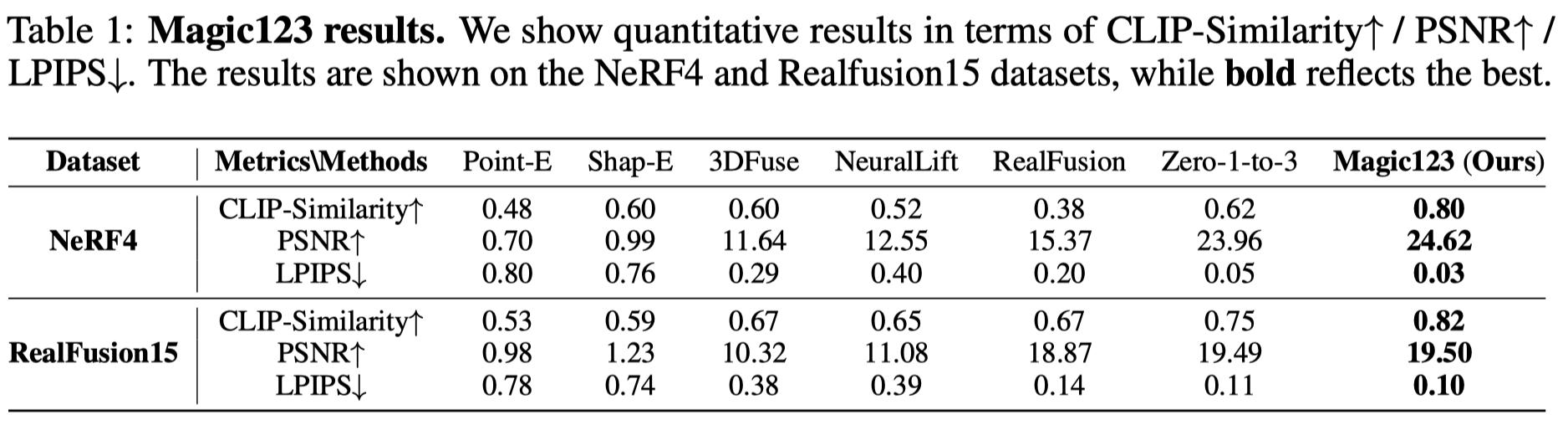
Quantitative Results
To demonstrate the effectiveness of the proposed Magic123, we evaluate its performance on the NeRF4 and RealFusion15 datasets. We conduct a comprehensive and quantitative comparison with multiple baselines for both datasets, as shown in Table I. Notably, our method achieves Top-1 performance across all the metrics when compared to previous SOTA approaches. This remarkable performance demonstrates the superiority of Magic123 and its ability to generate high-quality 3D representations.